

Anek Beñati mezu sekretu bat bidali nahi dio. Ez du burua gehiegi nekatu nahi eta zifratzeko metodo sinple bat aukeratu du: ordezkatze monoalfabetikoa deitzen dena.
Zertan datza? Har dezagun alfabetoa:
Alfabetoa = A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Orain, alfabetoaren hizkiak ausaz desordenatuko ditugu (eta hiztegi desordenatu horri gakoa deituko diogu):
Gakoa = J X A W Y Z E F B G H I K L P N Q R T U V D C M S O
Jarraian zifratu nahi dugun mezuaren hizki bakoitza gakoan dagokion hizkiaz ordezkatuko dugu. Adibidez, demagun zifratu nahi dugun testua “KAIXO” dela. Orduan:
Mezu Argia = K A I X O
Mezu sekretua (kriptograma) = H J B M P
Beñatek deszifratzeko, kontrako bidea jarraituko du,
Kriptograma = H J B M P
Mezu argia = K A I X O
Gakoa zein den jakinda, Beñatek kriptograma deszifratu egin du. Orain galdera da, segurtasunaren aldetik, sendoa al da zifratzeko erabili den prozedura hori? Alegia, gakoa zein den jakin gabe, kriptograma deszifratu daiteke? Orain dela asko erabaki zen prozedura hori ez zela segurua, zifratzeko erabili zen lengoaia zein den eta hizkuntza horretan erabiltzen diren hizkien maiztasuna baldin badakigu.
Al-Kindi matematikari irakiarrari (801 – 873) sor diogu kriptoanalisian erabiltzen den hizkien maiztasunaren azterketaren metodoa. Kriptoanalisian, mezu bat zifratzeko erabili den gakoa zein den jakin gabe, mezua deszifratzeko teknikak aztertzen dira.
Alboko oharra: Europan, hizkien maiztasunaren analisia garrantzitsua bilakatu zen 1450 hamarkadan, Johannes Gutenberg-en inprenta asmatu zuenean (1453). Bertan, hizki bakoitzak bere osagai mugikorra esleituta dauka. Osagai mugikor horiek antzinako idazteko makinetan bezala ikus daitezke. Garrantzitsua zen jakitea zeintzuk ziren testuetan gehien erabiltzen ziren hizkiak, horiek osagai mugikor gehiago edota sendoagoak behar lituzketelako.

- Irudia: Letra mugikorrekin egindako testua. Egilea: Willi Heidelbach / Wikipedia (CC-by) https://commons.wikimedia.org/wiki/File:Metal_movable_text.jpg
{kind=link}
Al-Kindik bazekien hizkuntza baten testu luzeetan, hizkien maiztasunak distribuzio jakin bat jarraitzen duela. Adibidez, ingelesezko testuetan gehien errepikatzen diren hizkiak eta horien maiztasuna erakusten duen taula hau da:

- Irudia: hizkien agerpen maiztasun taula, ingelesezko edozein testu luze baterako.
Bertan, gehien errepikatzen diren hizkiak e,t,a,o,i,n, eta s,h,r,d,l,u dira, hurrenez hurren. Bi letra multzo horiek horrela jartzen ziren, bi zutabeetan banatuta, linotipo motako inprenta makinetan, makina horien eragiketa mekanikoen abiadura handitzeko.

- Irudia: Linotipo motako inprenta makina baten teklatua. https://en.wikipedia.org/wiki/Linotype_machine#/media/File:ClavierLinotype_20041006-163300.jpg
{kind=link}
Bitxikeri bat gertatzen zen horrelako inprenta makinetan lerro moldeak egitean. Akats bat aurkitzen bazuten lerro baten erdian, lerro osoa bukatu eta lerro hori osatzeko erabili zen moldea baztertzea azkarragoa zen akatsa zegoen lerro punturaino sartutako hizkiak kentzea baino. Baina horretarako lerro akastuna bukatu egin behar zen, edozein letrekin bazen ere. Hori lortzeko lehenengo bi zutabeetatik behatzak modu azkarrean pasatzen zituzten, lerroan etaoin shrdlu idatziz. Horrelako patroia ikustean, inprentako langileek bazekiten lerro hori baztertu egin behar zela. Baina batzuetan, patroia ikusi ez eta azkenengo bertsioan inprimatu egiten zen.

- Irudia: 1903ko The New York Times egunkariko berri batean (azken-aurreko lerroan), etaoin shrdlu patroia bere burua erakusten. Iturria: https://www.nytimes.com/1903/10/30/archives/on-local-bowling-alleys.html
Baina gaztelaniaz, beste hizki batzuek osatzen dute maiztasun-sailkapen hori:

- Irudia: Gaztelaniazko hizkien agerpen maiztasun taula. Iturria: (cc-by-sa) https://es.wikipedia.org/wiki/Archivo:Frecuencia_de_uso_de_letras_en_espa%C3%B1ol.svg
{kind=link}
Gehien errepikatzen diren hizkiak, kasu honetan e,a,o,s, eta r dira.
Ordezkatze monoalfabetikoetan (gure adibidean erabili dugun metodoan), mezu argiaren hizki bakoitza gakoaren letra jakin bateagatik ordezkatzen dugu eta beti ordezkapen bera egingo dugu. Gure adibidean, mezu garbian A hizkia agertzen zen leku guztietan, J hizki bateaz ordezkatu dugu. X agertzen zen lekuetan M jarri dugu beti. Segurtasunaren aldetik, hori ahultasun bat da. Zergatik? Al-Kindik zioen bezala, nahikoa da kriptograman gehien agertzen den hizkia aurkitzea. Demagun, letra hori P dela. Mezu argia ingelesez dagoela baldin badakigu, orduan ziur asko kriptogramaren P horri dagokion mezu argiaren hizkia E dela esan dezakegu. Zergatik? E delako ingelesezko edozein mezu luze batean gehien errepikatuko den hizkia. Jarraian kriptograman gehien errepikatzen den hurrengo hizkia aurkitu eta ingelesez dagokion gehien errepikatzen den bigarren letrarekin parekatuko dugu.
Prozedura honek ez du beti hain modu errazean funtzionatuko. Batzuetan hizkuntza bateko bi hizkien agerpen maiztasuna ez baita oso ezberdina (adibidez, ingelesezko kasuan, i=6.966% eta n=6.749%). Orduan, kriptoanalisian bi ordezkapen horiek probatu eta agertzen diren hitzek zentzua duten edo ez ikusita, ordezkapen egokia zein den erabaki beharko dugu.
Baina gure kasura itzuliz, Ane eta Beñat euskaraz ari dira. Zein da hortaz, euskara hizkuntzan gehien errepikatzen diren hizkien taula? Bada, euskara mailan gehien dakienetariko eragile batengana jo (ElHuyar) eta gero, taula hori atzigarri ez dagoela jakin ondoren, https://twitter.com/juanan/status/773085922770448384, nire kabuz lortzea erabaki nuen.
Wikipedia korpus gisa
Nondik har dezakegu, modu errazean, euskaraz idatzitako testu multzo (oso) handi bat hizkien maiztasunaren kalkulua egiteko? Wikipediatik, ziur asko. Alegia, prozedura horrelakoa izango litzateke: Wikipedia-n euskaraz dauden artikulu guztiak hartu eta hizkien kontaketa egiteko prozedura pentsatu. Ez da zaila tresna egokiak izanez gero, baina gure eginbeharra hainbat pausutan banatuko dugu.
- Euskarazko Wikipediatik corpus osoa jaitsi.
- Corpus horretatik testu guztiak erauzi.
- Testuak aztertu hizkien maiztasuna kalkulatuz
Corpus osoa jaisteko, Wikipediak berak eskaintzen du modu erraz bat hurrengo estekan: https://dumps.wikimedia.org/euwiki/latest/. Bertan, euwiki-latest-pages-articles-multistream.xml.bz2 izeneko fitxategia jaitsiko dugu.
Arazoa da corpus horren edukia XML eta Markdown lengoiaetan idatzita dagoela eta parseatu egin behar dela, alegia, XML etiketak eta Markdown markak kendu, testu hutsa lortzeko. Horretarako, zorionez, bazegoen jada script bat (aplikazio bat) programatuta: https://github.com/bwbaugh/wikipedia-extractor. Corpusaren gainean aplikatu eta listo, badugu Wikipedia euskarazko testu guztiak.
Hizkien maiztasunaren kalkulua egiteko, R lengoian egindako beste script bat exekutatuko dugu.
https://gist.github.com/juananpe/2405f026e8aa5f7b6b91fd1c70e1ea95
Eta script hori 3 ordu exekutatzen utzi eta gero, azkenean, nahi genuen emaitza lortuko dugu!

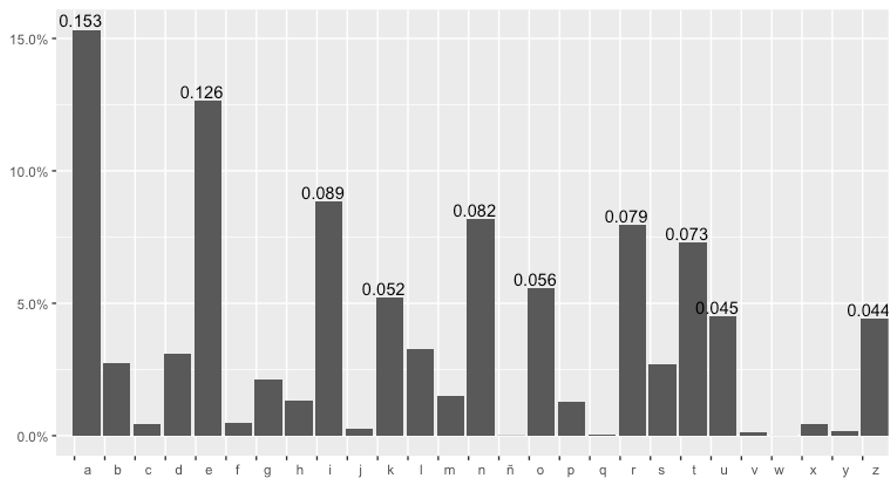
- Irudia: Euskarazko hizkien agerpen maiztasun taula.
Grafikoa lortzeko kodea: https://github.com/juananpe/hizkien-maiztasuna
Beraz, gehien errepikatzen diren hizkiak, euskaraz, a, e, i, n, r, t, o, k, u eta z dira. Goiko
grafikoan, ñ, q eta w ia ez dira ikusten, baina horrek ez du esan nahi agertzen ez direnik (atzerriko izenetan, adibidez). Izan ere, goiko taulan gorriz markatu dira hizki berezi horien agerpen maiztasuna, 0 ez direla azpimarratzeko.
{kind=link}