

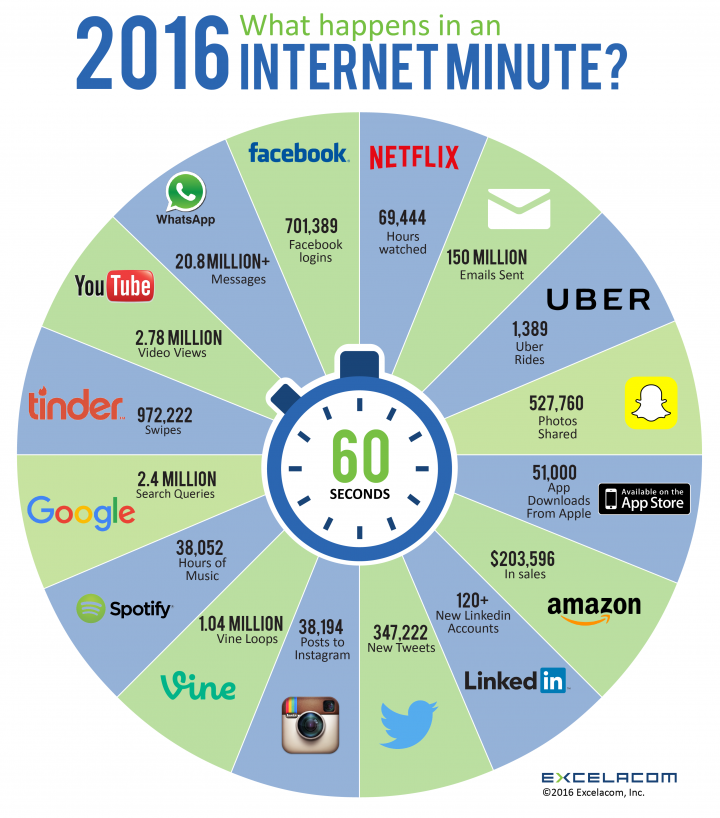
Egun, arlo askotariko informazio digitalizatua aurkitu daiteke nonahi, izan ere, segundoko Youtubera 5 bideo-ordu igotzen dira, Twitterren 5.700 milioi txio argitaratzen dira eta Facebooken 28 milioi eduki partekatzen dira.
Internet, M2M teknologiak edo Gauzen Internet, eta Sare Sozialek informazio oso baliotsua eskaintzen diete gaur egungo erakunde eta enpresei beraien inguruneaz eta erabiltzaileez. Baina informazio hori guztia erabat sakabanatuta dago hainbat iturrietako zerbitzarietan eta interneteko hodeian bertan ere. Gainera, informazioa mota askotariko datuez osaturik dago: idatzizko agiriak, datu-taulak, eduki grafikoak, ikus-entzunezkoak …, eta ohiko datu-analisi eta datu-base sistemek ez dute balio informazio hori guztia aztertu eta kudeatzeko.
Big Data datu-kopuru handia kudeatzeaz arduratzen den Informazio eta Komunikazio Teknologien esparrua da, hau da, datu horiek guztiak denbora errealean bilatu, aztertu eta erabiltzeko beharrezkoak diren teknikak eta teknologiak.
Big datako teknologia
Big data lantzeko tresna asko daude, adibidez, Hadoop, NoSQL, Cassandra,MongoDB, MapReduce,…, baina funtzean denak antzeko oinarria dute: makina edo nodo bat maisu bezala aritzen da, informazioa eta exekutatu beharreko algoritmoak gainontzeko nodo-langileen artean banatuz. Ondoren, batera, nodo-langile guztietan jasotako lana exekutatzen da, eta bukatzerakoan,emaitza maisu-lanak egiten dituen nodoari itzultzen diote. Nodo-langile batek, aldi berean, eta behar adina aldiz, bere lana beste azpinodo batzuentan bana dezake, zuhaitz itsurako egitura sortuz, exekutatu beharreko lana era eraginkor batean gauzatzeko tamaina aproposa izan arte. Egin beharreko lanaren zatiketa horri esker, nodo bakoitzaren lan-karga arinagoa da, eta egokiago gauzatu daiteke.

Big datako arkitektura
Orokorrean Big datako teknikak erabiltzen ditugunean, proiektu konplexuen aurrean gaude, eta lau ataletan banatzen ohi dira, atal bakoitzak bere nodo-egitura duelarik.

Txertatze fasea: Informazio iturriak anitzak izan daitezke eta API baten bidez txertatzen dira gure sisteman.
Moldaketa fasea: Txertatze fasetik gure sistemara heltzen diren landugabeko datuak eraldatu edo moldatu behar dira erabilgarri bihurtzeko. Zeregin horretan ETL (Extract, Transform and Load) tresnak erabiliko dira, datuetatik balioa duen informazioa ateratzeko eta hurrengo fasera bidaltzeko. Baliorik gabeko informazioa, berriz, arbuiatzen da memoria aurrezteko eta metatze fasea arintzeko.
Metatze fasea: Moldaketa fasetik datorren informazioa metatze-faseko nodoen artean banatzen da NoSQL –Not only SQL– tresnak erabiliz. Big datako datuak gordetzen dituen nodo taldeari Datu-Lakua edo Data-Lake deitu ohi zaio.
Analisi fasea: Big datako tresnekin metaturiko datuak aztertzeko algoritmo matematiko anitzetan oinarrituriko analisi-teknika bereziak erabiltzen dira, esaterako, datu-asoziazioa, datu-meatzaritza, multzokatze teknika, …
Teknologia hauek erabiltzen dituzten adibide ugari ditugu inguruan, baina nabarmenenak IKT mundutik datoz, hala nola Google, Facebook edota Amazon. Enpresa hauek beren erabiltzaileen bilioika bilaketak erabiltzen dituzte pertsonen gurariak iragartzeko eta asebete ditzaketen produktuak eskaintzeko. Eta maiz asmatzen dute.
Big data errealitate bat da gaur egun eta eskuragarri ditugun tresnei esker, edozein prozesutan eragina izan dezaketen aldagai gehienak irudika daitezke, denboran neurtu, aztertu eta hurrengo gertaerak iragarri litezke.

{kind=link}